近日,中国电子工业标准化技术协会批准并发布了《人工智能超节点服务器技术要求》等28项团体标准。其中由中国移动研究院牵头、奇异摩尔产品市场&研发部门主要参编的《人工智能加速器互联芯粒技术要求》标准(编号T/CESA 1457-2025)已获批准,并予以近日正式实施。此项标准是构建高性能“人工智能超节点服务器”的关键底层技术规范,旨在统一和规范加速器间的互联接口,促进不同AI芯片的互操作性与算力高效集成,对推动我国自主AI算力生态建设具有重要意义。
《人工智能加速器互联芯粒技术要求》标准始于中国移动研究院发起的全向智感互联架构(OISA)系统的标准与规范立项,其芯粒技术要求匹配OISA卡间互联协议生态。
互联芯粒作为OISA生态的关键模块赋能OISA协议层面统一报文格式、支持多语义融合、多层次流控重传以及集合通信加速等技术特点进一步实现高速、低时延、无损和高可靠的GPU通信。
标准背景与整体技术架构介绍
为了进一步提升AI网络互联系统级集成度与互联灵活性,业界开始探索在封装内部通过芯粒方式实现的Scale-up互联方案。该方案通过在芯片层面解耦计算与互联功能,从体系结构上为AI加速器的演进提供了新的思路和实现路径。
人工智能加速器互联芯粒的异构集成设计遵循模块化、标准化、开放化三大原则,旨在打破私有化互联方案的壁垒,构建跨厂商的智算生态:首先,芯粒应专注于数据传输功能,避免与其他芯粒功能耦合,每个芯粒需具备独立测试能力,减少封装后调试难度。其次,人工智能加速器互联芯粒与其他功能芯粒采用统一接口协议,确保不同厂商的芯粒可互操作,拥有标准的互联互通解决方案。最后,该人工智能加速器互联芯粒与多家技术厂商共同推动标准制定,推动半导体产业生态发展、降低成本、提高创新效率。
标准的整体架构要求
人工智能加速器互联芯粒要求将芯片内负责输入输出(I/O)相关功能单独作为芯片模块进行集成,作为一个独立的芯粒与其他计算芯粒、存储芯粒共同协作。本规范涉及的互联芯粒作用范围如图所示:
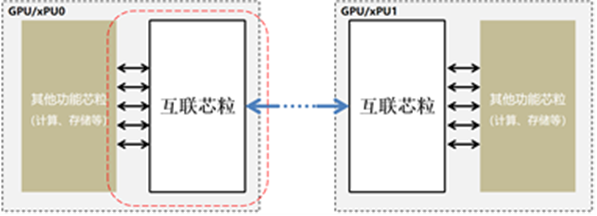
(图:人工智能加速器互联芯粒互联机制)
该标准明确GPU互联芯粒与其他功能芯粒间互联技术的应用场景、体系架构、接口要求、协议层、数据链路层、物理层、物理封装等多项技术要求。
互联协议规范
| 1 | 协议层 D2D互联机制、基于消息语义及内存语义的互联机制等 |
| 2 | 数据链路层 链路初始化、基于Flit的数据传输、错误检测与重传机制设计等 |
| 3 | 物理层 电气特性、时钟约束条件、信道均衡技术、误码控制等 |
接口实现要求
对于接口技术要求明确逻辑接口定义(针对不同场景的接口需求)
(图:互联芯粒核心接口示意图)
标准明确了互联芯粒在以上应用场景逻辑接口是否全面支持消息语义、内存语义及异构缓存一致互联的技术要求。在物理接口实现方向,互联芯粒的互联机制全面兼容UCIe Adv及UCIe std国际标准,涵盖在不同封装模式下凸点阵列布局与布线&设计规则等技术要求。
基于语义的通信工作流程
在人工智能加速器互联芯粒的通信架构中,基于内存语义的通信工作流程是OISA协议定义的关键操作。为高效满足GPU对消息传递与内存访问的特定语义需求,该标准同步设计了专用的OISA Bridge硬件模块及与之配套的低延时报文格式,共同构成了芯粒间高性能通信的实现基础。
(图:内存语义工作流程)
目前,IO芯粒被领先的国际厂商采用并已构成实际量产案例,如基于AMD MI300X以及Intel Ponte Vecchio(PVC)等AI加速器的互联方案均采用私有互联方案连接IO芯粒和计算芯粒。同时,头部云服务厂商AWS近日联合英伟达定制了基于NVLink Fusion技术的AI加速器,该方案同样通过专用IO芯粒实现服务器级别超大规模高性能互联。
本次《人工智能加速器互联芯粒技术要求》团体标准的发布是对奇异摩尔在GPU互联技术领域能力的高度认可,也标志着国产GPU互联技术从“跟随”逐步走向“定义”。标准的实施将推动形成基于开放芯粒架构的国产AI基础设施新范式,为构建自主可控的AI算力集群奠定坚实的技术基石。
推荐阅读: